Go map 底层换用 Swiss Table 性能提升近 50%
在 2024 年 11 月 5 日的 Go compiler and runtime meeting notes 中,我们注意到一个重要信息:来自字节的一位工程师在两年多前提出的「使用 Swiss table 重新实现 Go map」的建议即将落地,该 issue 已经被纳入 Go 1.24 里程碑。
什么是 Swiss Table
Swiss Table 是 Google 工程师于 2017 年开发的一种高效哈希表实现,旨在优化内存使用和提升性能。目前已被应用于多种编程语言:
- C++ Abseil 库的
flat_hash_map - Rust 标准库 HashMap 的默认实现
Google 工程师 Matt Kulukundis 在 2017 年 CppCon 大会上详细介绍了他们在 Swiss Table 上的工作:
https://www.youtube.com/watch?v=ncHmEUmJZf4
字节跳动的推动力
据 issue 描述,Go map 的 CPU 消耗约占服务总体开销的 4%。其中,map 的插入(mapassign)和访问(mapaccess)操作的 CPU 消耗几乎是 1:1。
以字节跳动这样大厂的体量,减少 1% 也意味着真金白银的大幅节省。字节工程师初版实现的基准测试结果显示,与原实现相比:
- 查询、插入、删除操作:提升 20%~50%
- 迭代性能:提升 10%
- 内存使用:减少 0%~25%
当前 Go map 的实现
在介绍 Go map 实现之前,我们先了解两种常见的哈希表实现方式:
开放寻址法(Open Addressing)
开放寻址法的核心思想是:当发生哈希碰撞时,按照一定的探测策略(线性探测、二次探测、双重哈希等)在哈希表中寻找下一个可用的空槽位。
优点:内存利用率高,缓存友好 缺点:探测时间不确定,最坏情况下为 O(n)
链式哈希法(Chaining)
链式哈希法采用「拉链法」,每个槽位(bucket)存储一个链表,所有哈希值相同的元素都存储在该链表中。Go map 的当前实现就采用了这种方式。
优点:插入和删除操作简单 缺点:需要额外的指针存储,内存开销相对较大
Go map 采用链式哈希
Go map 采用链式哈希(拉链法)实现:
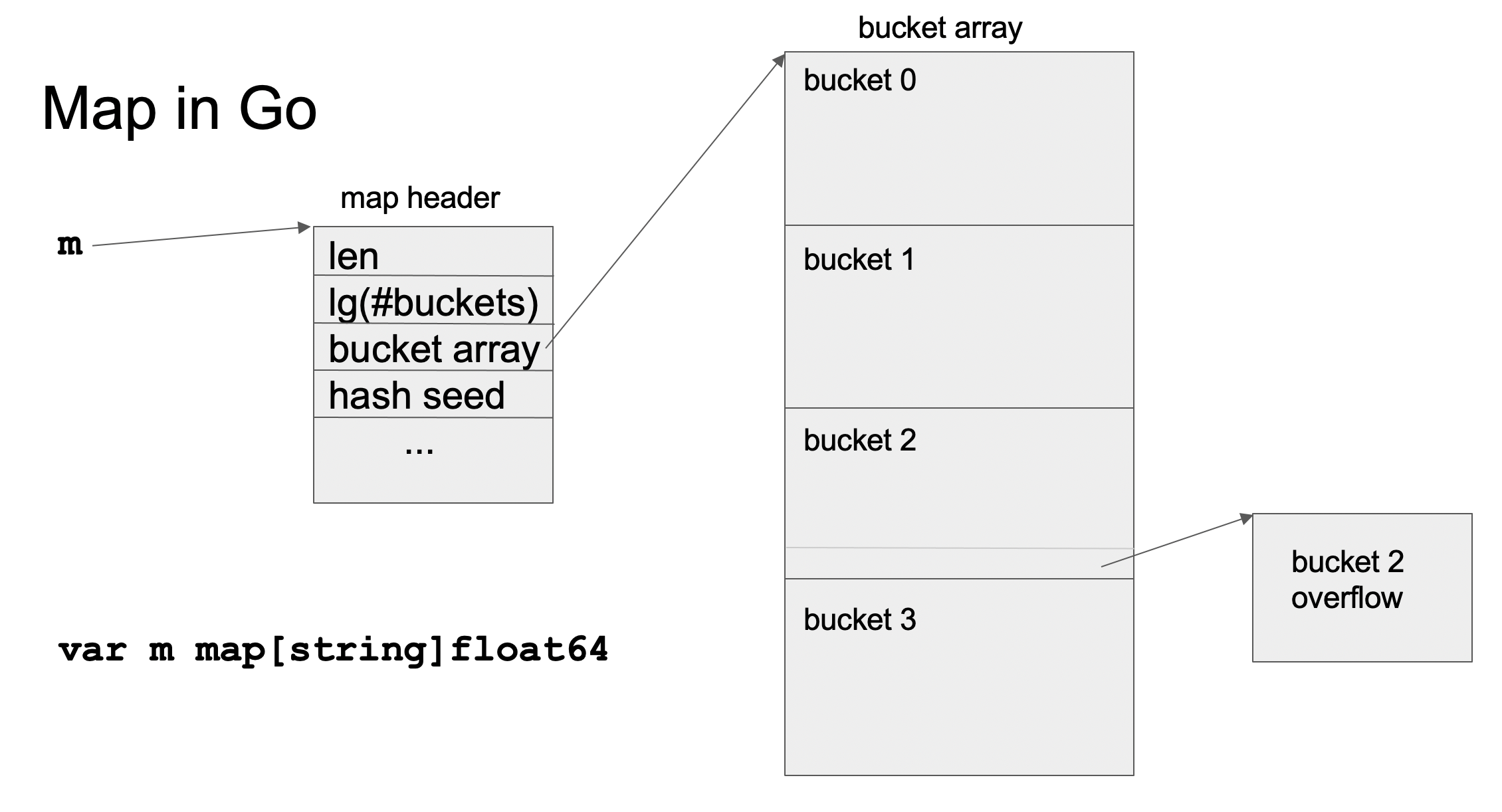
- 每个 bucket 可存储 8 个键值对
- 超过容量时创建 overflow bucket 存储多余数据
- 通过 load factor = 6.5 判定是否扩容
- 采用增量扩容,蚂蚁搬家式搬移元素
主要问题:
- 扩容后不再缩容,给内存带来压力
- 性能和延迟敏感场景下仍不够快
Swiss Table 的工作原理
Swiss Table 使用的不是拉链法,而是开放寻址。其核心思想是将数据分为 metadata array(控制字节数组) 和 slots array(数据槽数组) 两部分。
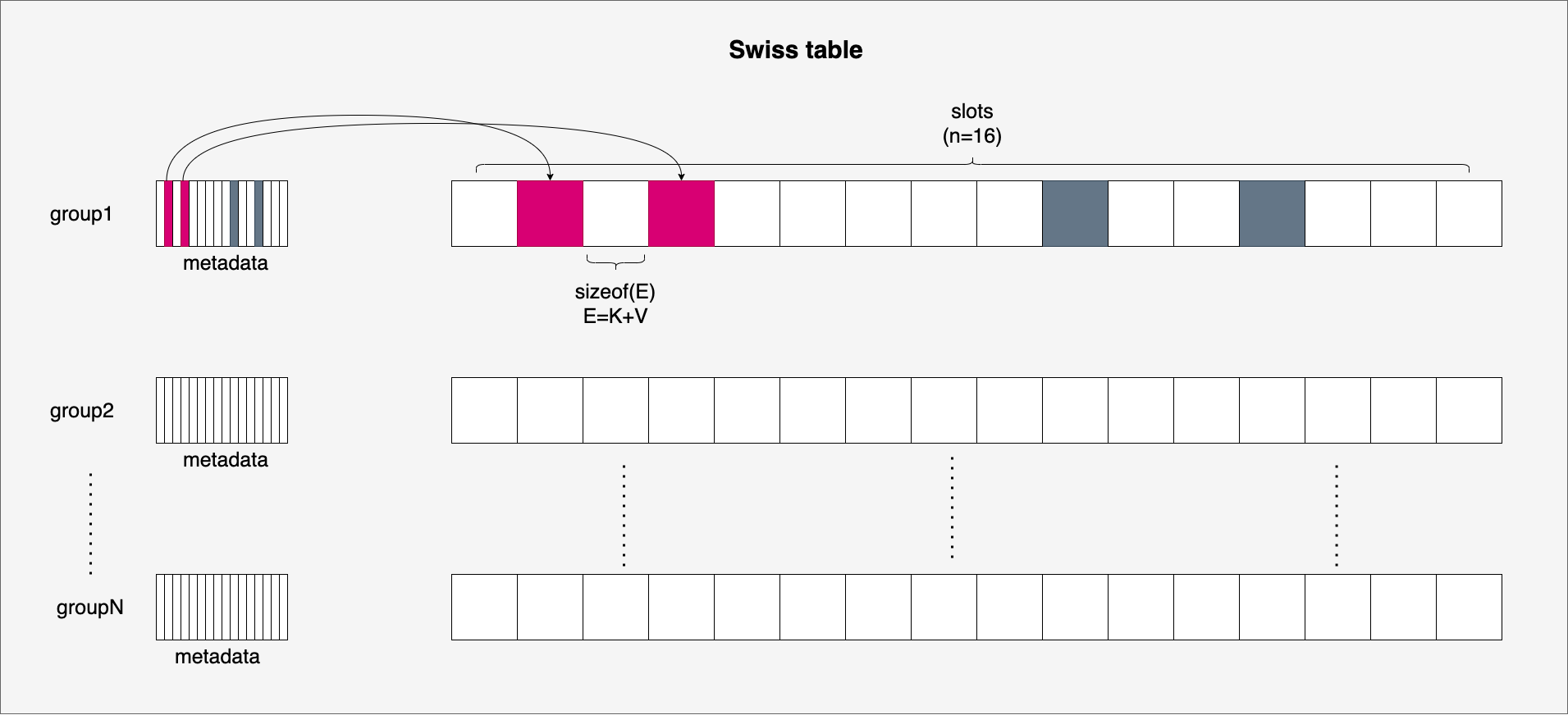
哈希值拆分:H1 与 H2
Swiss Table 将哈希值拆分为两部分:
- H1:哈希值的高位 bit,用于确定该元素属于哪个 Group(或 Slot)
- H2:哈希值的低 7 位,作为哈希指纹存储在 metadata 中,用于快速比对
H2 被存入对应 Slot 的控制字节中,由于控制字节只有 7 位可用空间,正好存放 H2。
控制字节的三种状态
每个控制字节由 1 个标志位 + 7 位 H2 哈希指纹组成:
| 控制字节 | 状态 |
|---|---|
1xxxxxxx(最高位为1,其余全零) | 空闲(Empty),该 Slot 从未被占用 |
0xxxxxxx(最高位为0,后7位为H2指纹) | 已使用(Full),该 Slot 存有数据 |
11111110 | 已删除(Tombstone),可重新使用 |
查找过程
- 计算哈希:对 key 进行哈希,得到 64 位哈希值
- 提取 H2 构建 Mask:用 H2 构造一个 16 字节的 Mask
- SIMD 并行比较:通过 SSE 指令一次性比较 16 个控制字节,快速排除不匹配的 Slot
- 精确匹配:对候选 Slot 进行完整的 key 比较,确认命中
这个过程就像「布隆过滤器」,能快速排除不可能的匹配项,减少不必要的内存访问。
SIMD 优化的原理
16 个条目的分组大小是基于 SSE2 寄存器长度(128bit = 16bytes) 和 CPU 缓存行大小(64字节) 优化的,保证了一个 Group 的控制字节能被单次 SIMD 指令处理。
Go tip 版本的实现
Go 团队在 Swiss Table 之上做了局部改进,引入了多 table 设计以支持渐进式扩容:
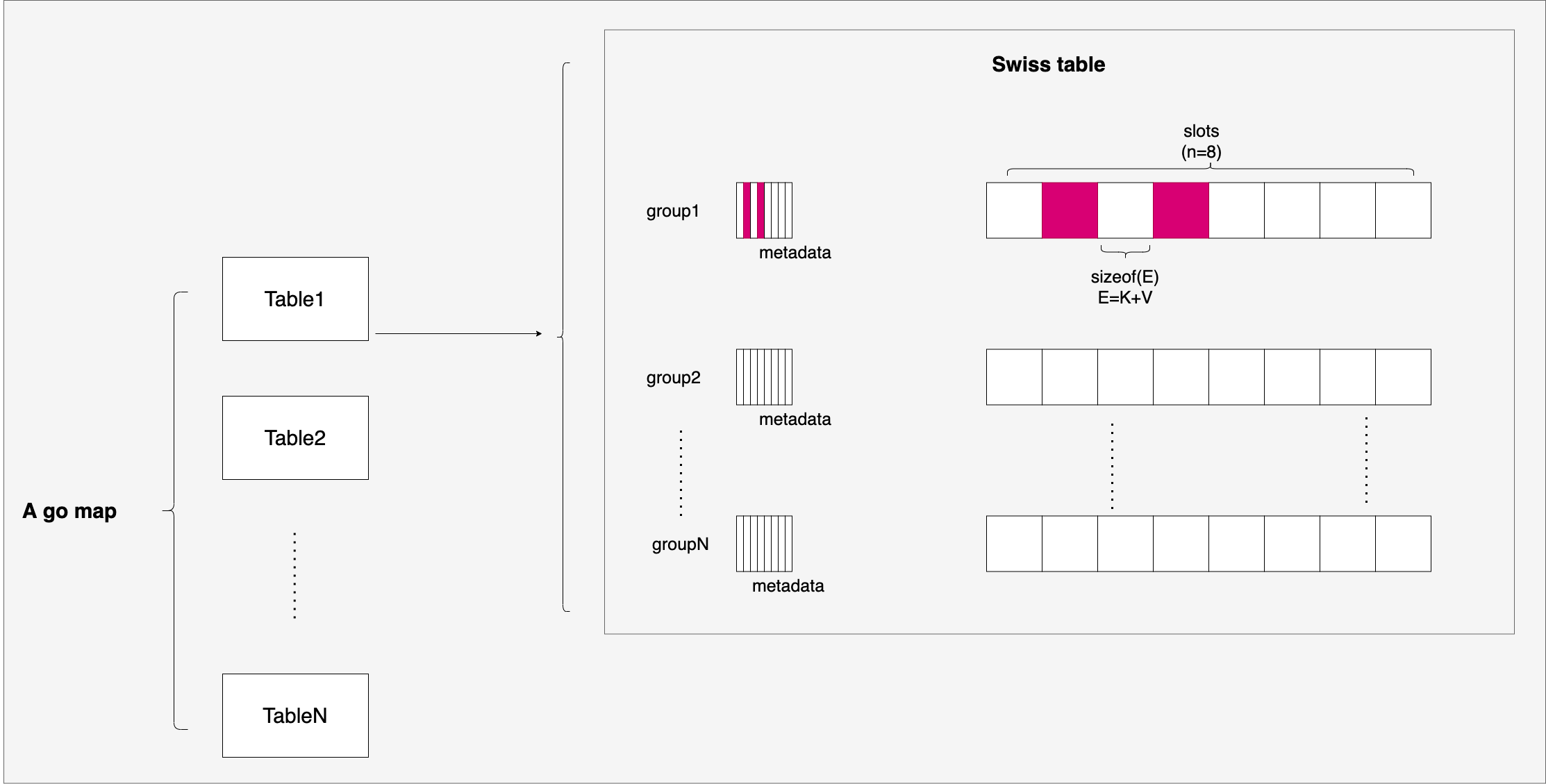
与 Abseil 原版的主要区别:
- Group 大小为 8 而非 16:Go 出于缓存行和寄存器友好的考虑,选择了 8 个 Slot
- 多 Table 设计:一个 map 实际上是多个 Swiss Table,通过 Extendible Hashing 管理
- 渐进式扩容:每个 table 可独立扩容,通过调整哈希位数(global depth)实现,每次只处理部分数据
- 二次探测:Go 使用二次探测(quadratic probing)而非线性探测
- Small Map 优化:少量元素(<=8)时直接使用单个 Group,避免性能回退
Extendible Hashing 示例
假设初始 global depth = 1,directory 指向 2 个 table:
- hash 前缀
0***→ table1 - hash 前缀
1***→ table2
当 table1 满了需要分裂时,global depth 扩为 2,table1 分裂为 table3(00**)和 table4(01**),table2 复用:
00**→ table301**→ table410**→ table211**→ table2
这样每次扩容只处理一个 table 的部分数据,延迟更加平滑。
Benchmark 性能对比
基于 Go 1.23.0 和 gotip(devel go1.24)的基准测试结果:
| 测试项 | 原实现 | Swiss Table | 提升 |
|---|---|---|---|
| MapAssignReuse/Int64/256 | 8.737µs | 4.716µs | 46% |
| MapAssignPreAllocate/Int64/256 | 10.412µs | 6.055µs | 42% |
| MapAccessHit/Int64/8192 | 25.99ns | 14.93ns | 43% |
| MapIter/Int/256 | 4.328µs | 3.748µs | 13% |
几何平均提升:15.11%
小结
经过两年多的实验与评估,Go 团队决定将 Swiss Table 作为 Go map 的底层实现,预计在 Go 1.24 中正式落地。新的实现不仅承继了原有的语义约束,还通过引入多表和渐进式扩容的设计,进一步优化了扩容过程的性能。
对于 Go 开发者来说,这是一个值得关注的重要改进特,别是在处理大规模数据或对性能敏感的场景中。